įĮüĒįĮČÓĄ─æ¬(y©®ng)ė├╔µ╝░ĄĮ┤¾öĄ(sh©┤)ō■(j©┤)Ż¼▀@ą®┤¾öĄ(sh©┤)ō■(j©┤)Ą─ī┘ąįŻ¼░³└©öĄ(sh©┤)┴┐Ż¼╦┘Č╚Ż¼ČÓśėąįĄ╚Ą╚Č╝╩Ū│╩¼F(xi©żn)┴╦┤¾öĄ(sh©┤)ō■(j©┤)▓╗öÓį÷ķLĄ─Å═(f©┤)ļsąįŻ¼╦∙ęįŻ¼┤¾öĄ(sh©┤)ō■(j©┤)Ą─Ęų╬÷ĘĮĘ©į┌┤¾öĄ(sh©┤)ō■(j©┤)ŅI(l©½ng)ė“Š═’@Ą├ė╚×ķųžę¬Ż¼┐╔ęįšf╩ŪøQČ©ūŅĮKą┼Žó╩ŪʱėąārųĄĄ─øQČ©ąįę“╦žĪŻ╗∙ė┌┤╦Ż¼┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷ĘĮĘ©└Ēšōėą──ą®─žŻ┐
┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─╬ÕéĆ╗∙▒ŠĘĮ├µ
PredictiveAnalyticCapabilitiesŻ©ŅA(y©┤)£yąįĘų╬÷─▄┴”Ż®
öĄ(sh©┤)ō■(j©┤)═┌Š“┐╔ęįūīĘų╬÷åTĖ³║├Ą─└ĒĮŌöĄ(sh©┤)ō■(j©┤)Ż¼Č°ŅA(y©┤)£yąįĘų╬÷┐╔ęįūīĘų╬÷åTĖ∙ō■(j©┤)┐╔ęĢ╗»Ęų╬÷║═öĄ(sh©┤)ō■(j©┤)═┌Š“Ą─ĮY(ji©”)╣¹ū÷│÷ę╗ą®ŅA(y©┤)£yąįĄ─┼ąöÓĪŻ
DataQualityandMasterDataManagementŻ©öĄ(sh©┤)ō■(j©┤)┘|(zh©¼)┴┐║═öĄ(sh©┤)ō■(j©┤)╣▄└ĒŻ®
öĄ(sh©┤)ō■(j©┤)┘|(zh©¼)┴┐║═öĄ(sh©┤)ō■(j©┤)╣▄└Ē╩Ūę╗ą®╣▄└ĒĘĮ├µĄ─ūŅ╝čīŹ█`ĪŻ═©▀^ś╦(bi©Īo)£╩(zh©│n)╗»Ą─┴„│╠║═╣żŠ▀ī”öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąą╠Ä└Ē┐╔ęį▒ŻūCę╗éĆŅA(y©┤)Ž╚Č©┴x║├Ą─Ė▀┘|(zh©¼)┴┐Ą─Ęų╬÷ĮY(ji©”)╣¹ĪŻ
AnalyticVisualizationsŻ©┐╔ęĢ╗»Ęų╬÷Ż®
▓╗╣▄╩Ūī”öĄ(sh©┤)ō■(j©┤)Ęų╬÷īŻ╝ę▀Ć╩ŪŲš═©ė├æ¶Ż¼öĄ(sh©┤)ō■(j©┤)┐╔ęĢ╗»╩ŪöĄ(sh©┤)ō■(j©┤)Ęų╬÷╣żŠ▀ūŅ╗∙▒ŠĄ─ę¬Ū¾ĪŻ┐╔ęĢ╗»┐╔ęįų▒ė^Ą─š╣╩ŠöĄ(sh©┤)ō■(j©┤)Ż¼ūīöĄ(sh©┤)ō■(j©┤)ūį╝║šfįÆŻ¼ūīė^▒Ŗ┬ĀĄĮĮY(ji©”)╣¹ĪŻ
SemanticEnginesŻ©šZ┴xę²ŪµŻ®
╬ęéāų¬Ą└ė╔ė┌ĘŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ą─ČÓśėąįĦüĒ┴╦öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─ą┬Ą─╠¶æ(zh©żn)Ż¼╬ęéāąĶę¬ę╗ŽĄ┴ąĄ─╣żŠ▀╚źĮŌ╬÷Ż¼╠ß╚ĪŻ¼Ęų╬÷öĄ(sh©┤)ō■(j©┤)ĪŻšZ┴xę²ŪµąĶę¬▒╗įO(sh©©)ėŗ│╔─▄ē“Å─“╬─Ön”ųąųŪ─▄╠ß╚Īą┼ŽóĪŻ
DataMiningAlgorithmsŻ©öĄ(sh©┤)ō■(j©┤)═┌Š“╦ŃĘ©Ż®
┐╔ęĢ╗»╩ŪĮo╚╦┐┤Ą─Ż¼öĄ(sh©┤)ō■(j©┤)═┌Š“Š═╩ŪĮoÖCŲ„┐┤Ą─ĪŻ╝»╚║ĪóĘųĖŅĪó╣┬┴ó³cĘų╬÷▀ĆėąŲõ╦¹Ą─╦ŃĘ©ūī╬ęéā╔Ņ╚ļöĄ(sh©┤)ō■(j©┤)ā╚(n©©i)▓┐Ż¼═┌Š“ārųĄĪŻ▀@ą®╦ŃĘ©▓╗āHę¬╠Ä└Ē┤¾öĄ(sh©┤)ō■(j©┤)Ą─┴┐Ż¼ę▓ę¬╠Ä└Ē┤¾öĄ(sh©┤)ō■(j©┤)Ą─╦┘Č╚ĪŻ
╝┘╚ń┤¾öĄ(sh©┤)ō■(j©┤)šµĄ─╩ŪŽ┬ę╗éĆųžę¬Ą─╝╝ąg(sh©┤)Ė’ą┬Ą─įÆŻ¼╬ęéāūŅ║├░čŠ½┴”ĻP(gu©Īn)ūóį┌┤¾öĄ(sh©┤)ō■(j©┤)─▄Įo╬ęéāĦüĒĄ─║├╠ÄŻ¼Č°▓╗āHāH╩Ū╠¶æ(zh©żn)ĪŻ
┤¾öĄ(sh©┤)ō■(j©┤)╠Ä└Ē
┤¾öĄ(sh©┤)ō■(j©┤)╠Ä└ĒöĄ(sh©┤)ō■(j©┤)Ģr┤·└Ē─ŅĄ─╚²┤¾▐D(zhu©Żn)ūāŻ║ę¬╚½¾w▓╗ę¬│ķśėŻ¼ę¬ą¦┬╩▓╗ę¬Į^ī”Š½┤_Ż¼ę¬ŽÓĻP(gu©Īn)▓╗ę¬ę“╣¹ĪŻŠ▀¾wĄ─┤¾öĄ(sh©┤)ō■(j©┤)╠Ä└ĒĘĮĘ©ŲõīŹėą║▄ČÓŻ¼Ą½╩ŪĖ∙ō■(j©┤)ķLĢrķgĄ─īŹ█`Ż¼╣Pš▀┐éĮY(ji©”)┴╦ę╗éĆ╗∙▒ŠĄ─┤¾öĄ(sh©┤)ō■(j©┤)╠Ä└Ē┴„│╠Ż¼▓óŪę▀@éĆ┴„│╠æ¬(y©®ng)įō─▄ē“?q©▒)”┤¾╝ę└ĒĒś┤¾ö?sh©┤)ō■(j©┤)Ą─╠Ä└Ēėą╦∙Ä═ų·ĪŻš¹éĆ╠Ä└Ē┴„│╠┐╔ęįĖ┼└©×ķ╦─▓ĮŻ¼Ęųäe╩Ū▓╔╝»Īóī¦(d©Żo)╚ļ║═ŅA(y©┤)╠Ä└ĒĪóĮy(t©»ng)ėŗ║═Ęų╬÷Ż¼ęį╝░═┌Š“ĪŻ
▓╔╝»
┤¾öĄ(sh©┤)ō■(j©┤)Ą─▓╔╝»╩ŪųĖ└¹ė├ČÓéĆöĄ(sh©┤)ō■(j©┤)ÄņüĒĮė╩š░l(f©Ī)ūį┐═æ¶Č╦Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▓óŪęė├æ¶┐╔ęį═©▀^▀@ą®öĄ(sh©┤)ō■(j©┤)ÄņüĒ▀M(j©¼n)ąą║åå╬Ą─▓ķįā║═╠Ä└Ē╣żū„ĪŻ▒╚╚ńŻ¼ļŖ╔╠Ģ■╩╣ė├é„Įy(t©»ng)Ą─ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)ÄņMySQL║═OracleĄ╚üĒ┤µā”├┐ę╗╣P╩┬äš(w©┤)öĄ(sh©┤)ō■(j©┤)Ż¼│²┤╦ų«═ŌŻ¼Redis║═MongoDB▀@śėĄ─NoSQLöĄ(sh©┤)ō■(j©┤)Äņę▓│Żė├ė┌öĄ(sh©┤)ō■(j©┤)Ą─▓╔╝»ĪŻ
į┌┤¾öĄ(sh©┤)ō■(j©┤)Ą─▓╔╝»▀^│╠ųąŻ¼Ųõų„ę¬╠ž³c║═╠¶æ(zh©żn)╩Ū▓ó░l(f©Ī)öĄ(sh©┤)Ė▀Ż¼ę“×ķ═¼Ģrėą┐╔─▄Ģ■ėą│╔Ū¦╔Ž╚fĄ─ė├æ¶üĒ▀M(j©¼n)ąąįLå¢║═▓┘ū„Ż¼▒╚╚ń╗▄ćŲ▒╩█Ų▒ŠW(w©Żng)šŠ║═╠įīÜŻ¼╦³éā▓ó░l(f©Ī)Ą─įLå¢┴┐į┌ĘÕųĄĢr▀_(d©ó)ĄĮ╔Ž░┘╚fŻ¼╦∙ęįąĶę¬į┌▓╔╝»Č╦▓┐╩┤¾┴┐öĄ(sh©┤)ō■(j©┤)Äņ▓┼─▄ų¦ō╬ĪŻ▓óŪę╚ń║╬į┌▀@ą®öĄ(sh©┤)ō■(j©┤)Äņų«ķg▀M(j©¼n)ąąžō(f©┤)▌dŠ∙║Ō║═ĘųŲ¼Ą─┤_╩ŪąĶę¬╔Ņ╚ļĄ─╦╝┐╝║═įO(sh©©)ėŗĪŻ
Įy(t©»ng)ėŗ/Ęų╬÷
Įy(t©»ng)ėŗ┼cĘų╬÷ų„ę¬└¹ė├Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŻ¼╗“š▀Ęų▓╝╩Įėŗ╦Ń╝»╚║üĒī”┤µā”ė┌Ųõā╚(n©©i)Ą─║Ż┴┐öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąŲš═©Ą─Ęų╬÷║═ĘųŅÉģR┐éĄ╚Ż¼ęįØMūŃ┤¾ČÓöĄ(sh©┤)│ŻęŖĄ─Ęų╬÷ąĶŪ¾Ż¼į┌▀@ĘĮ├µŻ¼ę╗ą®īŹĢrąįąĶŪ¾Ģ■ė├ĄĮEMCĄ─GreenPlumĪóOracleĄ─ExadataŻ¼ęį╝░╗∙ė┌MySQLĄ─┴ą╩Į┤µā”InfobrightĄ╚Ż¼Č°ę╗ą®┼·╠Ä└ĒŻ¼╗“š▀╗∙ė┌░ļĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ą─ąĶŪ¾┐╔ęį╩╣ė├HadoopĪŻĮy(t©»ng)ėŗ┼cĘų╬÷▀@▓┐ĘųĄ─ų„ę¬╠ž³c║═╠¶æ(zh©żn)╩ŪĘų╬÷╔µ╝░Ą─öĄ(sh©┤)ō■(j©┤)┴┐┤¾Ż¼Ųõī”ŽĄĮy(t©»ng)┘Yį┤Ż¼╠žäe╩ŪI/OĢ■ėąśO┤¾Ą─š╝ė├ĪŻ
ī¦(d©Żo)╚ļ/ŅA(y©┤)╠Ä└Ē
ļm╚╗▓╔╝»Č╦▒Š╔ĒĢ■ėą║▄ČÓöĄ(sh©┤)ō■(j©┤)ÄņŻ¼Ą½╩Ū╚ń╣¹ę¬ī”▀@ą®║Ż┴┐öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąėąą¦Ą─Ęų╬÷Ż¼▀Ć╩Ūæ¬(y©®ng)įōīó▀@ą®üĒūįŪ░Č╦Ą─öĄ(sh©┤)ō■(j©┤)ī¦(d©Żo)╚ļĄĮę╗éĆ╝»ųąĄ─┤¾ą═Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŻ¼╗“š▀Ęų▓╝╩Į┤µā”╝»╚║Ż¼▓óŪę┐╔ęįį┌ī¦(d©Żo)╚ļ╗∙ĄA(ch©│)╔Žū÷ę╗ą®║åå╬Ą─ŪÕŽ┤║═ŅA(y©┤)╠Ä└Ē╣żū„ĪŻę▓ėąę╗ą®ė├æ¶Ģ■į┌ī¦(d©Żo)╚ļĢr╩╣ė├üĒūįTwitterĄ─StormüĒī”öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąą┴„╩Įėŗ╦ŃŻ¼üĒØMūŃ▓┐ĘųśI(y©©)äš(w©┤)Ą─īŹĢrėŗ╦ŃąĶŪ¾ĪŻī¦(d©Żo)╚ļ┼cŅA(y©┤)╠Ä└Ē▀^│╠Ą─╠ž³c║═╠¶æ(zh©żn)ų„ę¬╩Ūī¦(d©Żo)╚ļĄ─öĄ(sh©┤)ō■(j©┤)┴┐┤¾Ż¼├┐├ļńŖĄ─ī¦(d©Żo)╚ļ┴┐Įø(j©®ng)│ŻĢ■▀_(d©ó)ĄĮ░┘šūŻ¼╔§ų┴Ū¦šū╝ēäeĪŻ
═┌Š“
┼cŪ░├µĮy(t©»ng)ėŗ║═Ęų╬÷▀^│╠▓╗═¼Ą─╩ŪŻ¼öĄ(sh©┤)ō■(j©┤)═┌Š“ę╗░Ńø]ėą╩▓├┤ŅA(y©┤)Ž╚įO(sh©©)Č©║├Ą─ų„Ņ}Ż¼ų„ę¬╩Ūį┌¼F(xi©żn)ėąöĄ(sh©┤)ō■(j©┤)╔Ž├µ▀M(j©¼n)ąą╗∙ė┌Ė„ĘN╦ŃĘ©Ą─ėŗ╦ŃŻ¼Å─Č°ŲĄĮŅA(y©┤)£yĄ─ą¦╣¹Ż¼Å─Č°īŹ¼F(xi©żn)ę╗ą®Ė▀╝ēäeöĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─ąĶŪ¾ĪŻ▒╚▌^Ąõą═╦ŃĘ©ėąė├ė┌Š█ŅÉĄ─K-MeansĪóė├ė┌Įy(t©»ng)ėŗīW(xu©”)┴Ģ(x©¬)Ą─SVM║═ė├ė┌ĘųŅÉĄ─Naive BayesŻ¼ų„ę¬╩╣ė├Ą─╣żŠ▀ėąHadoopĄ─MahoutĄ╚ĪŻįō▀^│╠Ą─╠ž³c║═╠¶æ(zh©żn)ų„ę¬╩Ūė├ė┌═┌Š“Ą─╦ŃĘ©║▄Å═(f©┤)ļsŻ¼▓óŪęėŗ╦Ń╔µ╝░Ą─öĄ(sh©┤)ō■(j©┤)┴┐║═ėŗ╦Ń┴┐Č╝║▄┤¾Ż¼▀ĆėąŻ¼│Żė├öĄ(sh©┤)ō■(j©┤)═┌Š“╦ŃĘ©Č╝ęįå╬ŠĆ│╠×ķų„ĪŻ
┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷╣żŠ▀įöĮŌ IBM╗▌Ųš╬ó▄ø╣żŠ▀į┌┴ą
╚ź─ĻŻ¼IBMą¹▓╝ęį17ā|├└į¬╩š┘ÅöĄ(sh©┤)ō■(j©┤)Ęų╬÷╣½╦ŠNetezzaŻ╗EMC└^╩š┘ÅöĄ(sh©┤)ō■(j©┤)é}Äņ▄ø╝■ÅS╔╠Greenplum║¾į┘┤╬╩š┘Å╝»╚║NASÅS╔╠IsilonŻ╗Teradata╩š┘Å┴╦Aster Data ╣½╦ŠŻ╗ļS║¾Ż¼╗▌Ųš╩š┘ÅīŹĢrĘų╬÷ŲĮ┼_VerticaĄ╚Ż¼▀@ą®╩š┘Å╩┬╝■ųĖŽ“Ą─╩Ū═¼ę╗éĆ─┐ś╦(bi©Īo)╩ął÷——┤¾öĄ(sh©┤)ō■(j©┤)ĪŻ╩ŪĄ─Ż¼┤¾öĄ(sh©┤)ō■(j©┤)Ģr┤·ęčĮø(j©®ng)üĒ┼RŻ¼┤¾╝ęČ╝į┌─”╚Ł▓┴šŲŻ¼ōīš╝╩ął÷Ž╚ÖCĪŻ
Č°į┌▀@└’├µŻ¼ūŅę½č█Ą─├„ąŪ╩ŪhadoopŻ¼Hadoopęč▒╗╣½šJ(r©©n)×ķ╩Ūą┬ę╗┤·Ą─┤¾öĄ(sh©┤)ō■(j©┤)╠Ä└ĒŲĮ┼_Ż¼EMCĪóIBMĪóInformaticaĪóMicrosoftęį╝░OracleČ╝╝Ŗ╝Ŗ═Č╚ļ┴╦HadoopĄ─æč▒¦ĪŻī”ė┌┤¾öĄ(sh©┤)ō■(j©┤)üĒšfŻ¼ūŅųžę¬Ą─▀Ć╩Ūī”ė┌öĄ(sh©┤)ō■(j©┤)Ą─Ęų╬÷Ż¼Å─└’├µīżšęėąārųĄĄ─öĄ(sh©┤)ō■(j©┤)Ä═ų·Ų¾śI(y©©)ū„│÷Ė³║├Ą─╔╠śI(y©©)øQ▓▀ĪŻŽ┬├µŻ¼╬ęéāŠ═üĒ┐┤ęįŽ┬░╦┤¾ĻP(gu©Īn)ė┌┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─╣żŠ▀ĪŻ
EMC GreenplumĮy(t©»ng)ę╗Ęų╬÷ŲĮ┼_(UAP)

Greenplumį┌2010─Ļ▒╗EMC╩š┘Å┴╦ŲõEMC GreenplumĮy(t©»ng)ę╗Ęų╬÷ŲĮ┼_Ż©UAPŻ®╩Ūę╗┐Ņå╬ę╗▄ø╝■ŲĮ┼_Ż¼öĄ(sh©┤)ō■(j©┤)łFĻĀ║═Ęų╬÷łFĻĀ┐╔ęįį┌įōŲĮ┼_╔Ž¤o┐pĄž╣▓ŽĒą┼ŽóĪóģf(xi©”)ū„Ęų╬÷Ż¼ø]▒žę¬į┌▓╗═¼Ą─╣┬Źu╔Ž╣żū„Ż¼╗“š▀į┌▓╗═¼Ą─╣┬Źuų«ķg▐D(zhu©Żn)ęŲöĄ(sh©┤)ō■(j©┤)ĪŻš²ę“×ķ╚ń┤╦Ż¼UAP░³└©ECM GreenplumĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĪóEMC Greenplum HD Hadoop░l(f©Ī)ąą░µ║═EMC Greenplum ChorusĪŻ
EMC×ķ┤¾öĄ(sh©┤)ō■(j©┤)ķ_░l(f©Ī)Ą─ė▓╝■╩Ū─ŻēK╗»Ą─EMCöĄ(sh©┤)ō■(j©┤)ėŗ╦ŃįO(sh©©)éõŻ©DCAŻ®Ż¼╦³─▄ē“į┌ę╗éĆįO(sh©©)éõ└’├µ▀\ąą▓óöUš╣GreenplumĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ║═Greenplum HD╣Ø(ji©”)³cĪŻDCA╠ß╣®┴╦ę╗éĆ╣▓ŽĒĄ─ųĖō]ųąą─Ż©Command CenterŻ®Įń├µŻ¼ūī╣▄└ĒåT┐╔ęį▒O(ji©Īn)┐žĪó╣▄└Ē║═┼õų├GreenplumöĄ(sh©┤)ō■(j©┤)Äņ║═HadoopŽĄĮy(t©»ng)ąį─▄╝░╚▌┴┐ĪŻļSų°HadoopŲĮ┼_╚š┌ģ│╔╩ņŻ¼ŅA(y©┤)ėŗĘų╬÷╣”─▄Ģ■╝▒äĪį÷╝ėĪŻ
IBM┤“ĮM║Ž╚Ł╠ß╣®BigInsights║═BigCloud
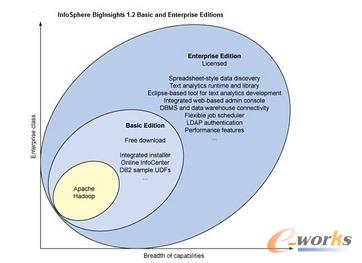
Äū─ĻŪ░Ż¼IBMķ_╩╝į┌ŲõīŹ“×╩ęćLįć╩╣ė├HadoopŻ¼Ą½╩Ū╦³į┌╚ź─ĻīóŽÓĻP(gu©Īn)«a(ch©Żn)ŲĘ║═Ę■äš(w©┤)╝{╚ļĄĮ╔╠śI(y©©)░µIBMį┌╚ź─Ļ5į┬═Ų│÷┴╦InfoSphere BigIįŲ░µ▒ŠĄ─ InfoSphere BigInsights╩╣ĮM┐Śā╚(n©©i)Ą─╚╬║╬ė├æ¶Č╝┐╔ęįū÷┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷ĪŻįŲ╔ŽĄ─BigInsights▄ø╝■┐╔ęįĘų╬÷öĄ(sh©┤)ō■(j©┤)Äņ└’Ą─ĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)║═ĘŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ż¼╩╣øQ▓▀š▀─▄ē“čĖ╦┘īóČ┤▓ņ▐D(zhu©Żn)╗»×ķąąäėĪŻ
IBMļS║¾ėųį┌10į┬═©▀^ŲõųŪ╗█įŲŲ¾śI(y©©)Ż©SmartCloud EntERPriseŻ®╗∙ĄA(ch©│)╝▄śŗ(g©░u)Ż¼īóBigInsights║═BigSheetsū„×ķę╗ĒŚĘ■äš(w©┤)üĒ╠ß╣®ĪŻ▀@ĒŚĘ■äš(w©┤)Ęų╗∙ĄA(ch©│)░µ║═Ų¾śI(y©©)░µŻ╗ę╗┤¾┘u³cŠ═╩Ū┐═æ¶▓╗▒ž┘Å┘Ių¦│ųąįė▓╝■Ż¼ę▓▓╗ąĶę¬ITīŻķTų¬ūRŻ¼Š═┐╔ęįīW(xu©”)┴Ģ(x©¬)║═įćė├┤¾öĄ(sh©┤)ō■(j©┤)╠Ä└Ē║═Ęų╬÷╣”─▄ĪŻō■(j©┤)IBM┬ĢĘQŻ¼┐═æ¶ė├▓╗┴╦30ĘųńŖŠ═─▄┤ŅĮ©ŲHadoop╝»╚║Ż¼▓óīóöĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ęŲĄĮ╝»╚║└’├µŻ¼öĄ(sh©┤)ō■(j©┤)╠Ä└Ē┘Mė├╩Ū├┐éĆ╝»╚║├┐ąĪĢr60├└ĘųŲārĪŻ
Informatica 9.1Ż║īó┤¾öĄ(sh©┤)ō■(j©┤)Ą─╠¶æ(zh©żn)▐D(zhu©Żn)╗»×ķ┤¾ÖCė÷
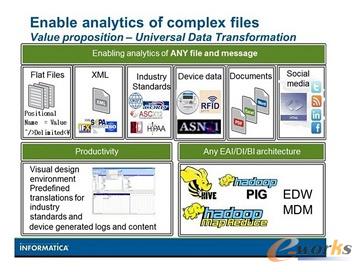
Informatica╣½╦Šį┌╚ź─Ļ10į┬ätĖ³╔Ņ╚ļę╗▓ĮŻ¼«ö(d©Īng)Ģr╦³═Ų│÷┴╦HParserŻ¼▀@╩Ūę╗ĘNßśī”HadoopČ°ā×(y©Łu)╗»Ą─öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQŁh(hu©ón)Š│ĪŻō■(j©┤)Informatica┬ĢĘQŻ¼▄ø╝■ų¦│ųņ`╗ŅĖ▀ą¦Ąž╠Ä└ĒHadoop└’├µĄ─╚╬║╬╬─╝■Ė±╩ĮŻ¼×ķHadoopķ_░l(f©Ī)╚╦åT╠ß╣®┴╦╝┤ķ_╝┤ė├Ą─ĮŌ╬÷╣”─▄Ż¼ęį▒Ń╠Ä└ĒÅ═(f©┤)ļsČ°ČÓśėĄ─öĄ(sh©┤)ō■(j©┤)į┤Ż¼░³└©╚šųŠĪó╬─ÖnĪóČ■▀M(j©¼n)ųŲöĄ(sh©┤)ō■(j©┤)╗“?q©▒)ė┤╬╩Įö?sh©┤)ō■(j©┤)Ż¼ęį╝░▒ŖČÓąąśI(y©©)ś╦(bi©Īo)£╩(zh©│n)Ė±╩ĮŻ©╚ńŃyąąśI(y©©)Ą─NACHAĪóų¦ĖČśI(y©©)Ą─SWIFTĪóĮ╚┌öĄ(sh©┤)ō■(j©┤)śI(y©©)Ą─FIX║═▒ŻļUśI(y©©)Ą─ACORDŻ®ĪŻš²╚ńöĄ(sh©┤)ō■(j©┤)Äņā╚(n©©i)╠Ä└Ē╝╝ąg(sh©┤)╝ė┐ņ┴╦Ė„ĘNĘų╬÷ĘĮĘ©Ż¼Informatica═¼śėīóĮŌ╬÷┤·┤a╠Ē╝ėĄĮHadoop└’├µŻ¼ęį▒Ń│õĘų└¹ė├╦∙ėą▀@ą®╠Ä└Ē╣”─▄Ż¼▓╗Š├Ģ■╠Ē╝ėŲõ╦¹Ą─öĄ(sh©┤)ō■(j©┤)╠Ä└Ē┤·┤aĪŻ
Informatica HParser╩ŪInformatica B2B Data Exchange╝ęūÕ«a(ch©Żn)ŲĘ╝░InformaticaŲĮ┼_Ą─ūŅą┬ča│õŻ¼ų╝į┌ØMūŃÅ─║Ż┴┐¤oĮY(ji©”)śŗ(g©░u)öĄ(sh©┤)ō■(j©┤)ųą╠ß╚Ī╔╠śI(y©©)ārųĄĄ─╚šęµį÷ķLĄ─ąĶŪ¾ĪŻ╚ź─ĻŻ¼ Informatica│╔╣”Ąž═Ų│÷┴╦äō(chu©żng)ą┬Ą─Informatica 9.1 for Big DataŻ¼╩Ū╚½Ū“Ą┌ę╗éĆīŻķT×ķ┤¾öĄ(sh©┤)ō■(j©┤)Č°śŗ(g©░u)Į©Ą─Įy(t©»ng)ę╗öĄ(sh©┤)ō■(j©┤)╝»│╔ŲĮ┼_ĪŻ
╝ū╣Ū╬─┤¾öĄ(sh©┤)ō■(j©┤)ÖC——Oracle Big Data Appliance
╝ū╣Ū╬─Ą─Big Data Appliance╝»│╔ŽĄĮy(t©»ng)░³└©ClouderaĄ─HadoopŽĄĮy(t©»ng)╣▄└Ē▄ø╝■║═ų¦│ųĘ■äš(w©┤)Apache Hadoop ║═Cloudera ManagerĪŻ╝ū╣Ū╬─ęĢBig Data Appliance×ķ░³└©ExadataĪó Exalogic║═ Exalytics In-Memory MachineĄ─“Į©įņŽĄĮy(t©»ng)”ĪŻOracle┤¾öĄ(sh©┤)ō■(j©┤)ÖC(Oracle Big Data Appliance)Ż¼╩Ūę╗éĆ▄øĪóė▓╝■╝»│╔ŽĄĮy(t©»ng)Ż¼į┌ŽĄĮy(t©»ng)ųą╚┌╚ļ┴╦ClouderaĄ─Distribution Including Apache HadoopĪóCloudera Manager║═ę╗éĆķ_į┤RĪŻįō┤¾öĄ(sh©┤)ō■(j©┤)ÖC▓╔ė├Oracle Linux▓┘ū„ŽĄĮy(t©»ng)Ż¼▓ó┼õéõOracle NoSQLöĄ(sh©┤)ō■(j©┤)Äņ╔ńģ^(q©▒)░µ▒Š║═Oracle HotSpot Java╠ōöMÖCĪŻBig Data Appliance×ķ╚½╝▄śŗ(g©░u)«a(ch©Żn)ŲĘŻ¼├┐éĆ╝▄śŗ(g©░u)864GB┤µā”Ż¼216éĆCPUā╚(n©©i)║╦Ż¼648TBRAW┤µā”Ż¼├┐├ļ40GBĄ─InifiniBand▀BĮėĪŻBig Data Appliance╩█ār45╚f├└į¬Ż¼├┐─Ļė▓▄ø╝■ų¦│ų┘Mė├×ķ12%ĪŻ
╝ū╣Ū╬─Big Data Appliance┼cEMC Data Computing ApplianceŲźö│Ż¼IBMę▓į°═Ų│÷öĄ(sh©┤)ō■(j©┤)Ęų╬÷▄ø╝■ŲĮ┼_InfoSphere BigInsightsŻ¼╬ó▄øę▓ą¹▓╝į┌2012─Ļ░l(f©Ī)▓╝Hadoop╝▄śŗ(g©░u)Ą─SQL Server 2012┤¾ą═öĄ(sh©┤)ō■(j©┤)╠Ä└ĒŲĮ┼_ĪŻ
Įy(t©»ng)ėŗĘų╬÷ĘĮĘ©ęį╝░Įy(t©»ng)ėŗ▄ø╝■įö╝Ü(x©¼)ĮķĮB

Įy(t©»ng)ėŗĘų╬÷ĘĮĘ©ėą──ÄūĘNŻ┐Ž┬├µ╬ęéāīóįö╝Ü(x©¼)ĻU╩÷Ż¼▓óĮķĮBę╗ą®│Żė├Ą─Įy(t©»ng)ėŗĘų╬÷▄ø╝■ĪŻ
ę╗ĪóųĖś╦(bi©Īo)ī”▒╚Ęų╬÷Ę©ųĖś╦(bi©Īo)ī”▒╚Ęų╬÷Ę©
Įy(t©»ng)ėŗĘų╬÷Ą─░╦ĘNĘĮĘ©ę╗ĪóųĖś╦(bi©Īo)ī”▒╚Ęų╬÷Ę©ųĖś╦(bi©Īo)ī”▒╚Ęų╬÷Ę©Ż¼ėųĘQ▒╚▌^Ęų╬÷Ę©Ż¼╩ŪĮy(t©»ng)ėŗĘų╬÷ųąūŅ│Żė├Ą─ĘĮĘ©ĪŻ╩Ū═©▀^ėąĻP(gu©Īn)Ą─ųĖś╦(bi©Īo)ī”▒╚üĒĘ┤ė│╩┬╬’öĄ(sh©┤)┴┐╔Ž▓Ņ«É║═ūā╗»Ą─ĘĮĘ©ĪŻėą▒╚▌^▓┼─▄ĶbäeĪŻå╬¬Ü┐┤ę╗ą®ųĖś╦(bi©Īo)Ż¼ų╗─▄šf├„┐é¾wĄ──│ą®öĄ(sh©┤)┴┐╠žš„Ż¼Ą├▓╗│÷╩▓├┤ĮY(ji©”)šōąįĄ─šJ(r©©n)ūRŻ╗ę╗Įø(j©®ng)▀^▒╚▌^Ż¼╚ń┼cć°═ŌĪó═Ōå╬╬╗▒╚Ż¼┼cÜv╩ĘöĄ(sh©┤)ō■(j©┤)▒╚Ż¼┼cėŗäØŽÓ▒╚Ż¼Š═┐╔ęįī”ęÄ(gu©®)─Ż┤¾ąĪĪó╦«ŲĮĖ▀Ą═Īó╦┘Č╚┐ņ┬²ū„│÷┼ąöÓ║═įuārĪŻ
ųĖś╦(bi©Īo)Ęų╬÷ī”▒╚Ęų╬÷ĘĮĘ©┐╔Ęų×ķņoæB(t©żi)▒╚▌^║═äėæB(t©żi)▒╚▌^Ęų╬÷ĪŻņoæB(t©żi)▒╚▌^╩Ū═¼ę╗ĢrķgŚl╝■Ž┬▓╗═¼┐é¾wųĖś╦(bi©Īo)▒╚▌^Ż¼╚ń▓╗═¼▓┐ķTĪó▓╗═¼Ąžģ^(q©▒)Īó▓╗═¼ć°╝ęĄ─▒╚▌^Ż¼ę▓ĮąÖMŽ“▒╚▌^Ż╗äėæB(t©żi)▒╚▌^╩Ū═¼ę╗┐é¾wŚl╝■▓╗═¼ĢrŲ┌ųĖś╦(bi©Īo)öĄ(sh©┤)ųĄĄ─▒╚▌^Ż¼ę▓Įą┐vŽ“▒╚▌^ĪŻ▀@ā╔ĘNĘĮĘ©╝╚┐╔å╬¬Ü╩╣ė├Ż¼ę▓┐╔ĮY(ji©”)║Ž╩╣ė├ĪŻ▀M(j©¼n)ąąī”▒╚Ęų╬÷ĢrŻ¼┐╔ęįå╬¬Ü╩╣ė├┐é┴┐ųĖś╦(bi©Īo)╗“ŽÓī”ųĖś╦(bi©Īo)╗“ŲĮŠ∙ųĖś╦(bi©Īo)Ż¼ę▓┐╔īó╦³éāĮY(ji©”)║ŽŲüĒ▀M(j©¼n)ąąī”▒╚ĪŻ▒╚▌^Ą─ĮY(ji©”)╣¹┐╔ė├ŽÓī”öĄ(sh©┤)Ż¼╚ń░┘Ęų?j©½n)?sh©┤)Īó▒ČöĄ(sh©┤)ĪóŽĄöĄ(sh©┤)Ą╚Ż¼ę▓┐╔ė├ŽÓ▓ŅĄ─Į^ī”öĄ(sh©┤)║═ŽÓĻP(gu©Īn)Ą─░┘Ęų³cŻ©├┐1Żź×ķę╗éĆ░┘Ęų³cŻ®üĒ▒Ē╩ŠŻ¼╝┤īóī”▒╚Ą─ųĖś╦(bi©Īo)ŽÓ£pĪŻ
Č■ĪóĘųĮMĘų╬÷Ę©ųĖś╦(bi©Īo)ī”▒╚Ęų╬÷Ę©
ĘųĮMĘų╬÷Ę©ųĖś╦(bi©Īo)ī”▒╚Ęų╬÷Ę©ī”▒╚Ż¼Ą½ĮM│╔Įy(t©»ng)ėŗ┐é¾wĄ─Ė„å╬╬╗Š▀ėąČÓĘN╠žš„Ż¼▀@Š═╩╣Ą├į┌═¼ę╗┐é¾wĘČć·ā╚(n©©i)Ą─Ė„å╬╬╗ų«ķg«a(ch©Żn)╔·┴╦įSČÓ▓ŅäeŻ¼Įy(t©»ng)ėŗĘų╬÷▓╗āHę¬ī”┐é¾wöĄ(sh©┤)┴┐╠žš„║═öĄ(sh©┤)┴┐ĻP(gu©Īn)ŽĄ▀M(j©¼n)ąąĘų╬÷Ż¼▀Ćę¬╔Ņ╚ļ┐é¾wĄ─ā╚(n©©i)▓┐▀M(j©¼n)ąąĘųĮMĘų╬÷ĪŻĘųĮMĘų╬÷Ę©Š═╩ŪĖ∙ō■(j©┤)Įy(t©»ng)ėŗĘų╬÷Ą──┐Ą─ę¬Ū¾Ż¼░č╦∙蹊┐Ą─┐é¾w░┤ššę╗éĆ╗“š▀ÄūéĆś╦(bi©Īo)ųŠäØĘų×ķ╚¶Ė╔éĆ▓┐ĘųŻ¼╝ėęįš¹└ĒŻ¼▀M(j©¼n)ąąė^▓ņĪóĘų╬÷Ż¼ęįĮę╩ŠŲõā╚(n©©i)į┌Ą─┬ō(li©ón)ŽĄ║═ęÄ(gu©®)┬╔ąįĪŻ
Įy(t©»ng)ėŗĘųĮMĘ©Ą─ĻP(gu©Īn)µIå¢Ņ}į┌ė┌š²┤_▀xō±ĘųĮMś╦(bi©Īo)ųĄ║═äØĘųĖ„ĮMĮńŽ▐ĪŻ
╚²ĪóĢrķgöĄ(sh©┤)┴ą╝░äėæB(t©żi)Ęų╬÷Ę©
ĢrķgöĄ(sh©┤)┴ąĪŻ╩Ūīó═¼ę╗ųĖś╦(bi©Īo)į┌Ģrķg╔Žūā╗»║═░l(f©Ī)š╣Ą─ę╗ŽĄ┴ąöĄ(sh©┤)ųĄŻ¼░┤ĢrķgŽ╚║¾Ēśą“┼┼┴ąŻ¼Š═ą╬│╔ĢrķgöĄ(sh©┤)┴ąŻ¼ėųĘQäėæB(t©żi)öĄ(sh©┤)┴ąĪŻ╦³─▄Ę┤ė│╔ńĢ■Įø(j©®ng)Ø·¼F(xi©żn)Ž¾Ą─░l(f©Ī)š╣ūāäėŪķørŻ¼═©▀^ĢrķgöĄ(sh©┤)┴ąĄ─ŠÄųŲ║═Ęų╬÷Ż¼┐╔ęįšę│÷äėæB(t©żi)ūā╗»ęÄ(gu©®)┬╔Ż¼×ķŅA(y©┤)£y╬┤üĒĄ─░l(f©Ī)š╣┌ģä▌╠ß╣®ę└ō■(j©┤)ĪŻĢrķgöĄ(sh©┤)┴ą┐╔Ęų×ķĮ^ī”öĄ(sh©┤)ĢrķgöĄ(sh©┤)┴ąĪóŽÓī”öĄ(sh©┤)ĢrķgöĄ(sh©┤)┴ąĪóŲĮŠ∙öĄ(sh©┤)ĢrķgöĄ(sh©┤)┴ąĪŻ
ĢrķgöĄ(sh©┤)┴ą╦┘Č╚ųĖś╦(bi©Īo)ĪŻĖ∙ō■(j©┤)Į^ī”öĄ(sh©┤)ĢrķgöĄ(sh©┤)┴ą┐╔ęįėŗ╦ŃĄ─╦┘Č╚ųĖś╦(bi©Īo)Ż║ėą░l(f©Ī)š╣╦┘Č╚Īóį÷ķL╦┘Č╚ĪóŲĮŠ∙░l(f©Ī)š╣╦┘Č╚ĪóŲĮŠ∙į÷ķL╦┘Č╚ĪŻ
äėæB(t©żi)Ęų╬÷Ę©ĪŻį┌Įy(t©»ng)ėŗĘų╬÷ųąŻ¼╚ń╣¹ų╗ėą╣┬┴óĄ─ę╗éĆĢrŲ┌ųĖś╦(bi©Īo)ųĄŻ¼╩Ū║▄ļyū„│÷┼ąöÓĄ─ĪŻ╚ń╣¹ŠÄųŲ┴╦ĢrķgöĄ(sh©┤)┴ąŻ¼Š═┐╔ęį▀M(j©¼n)ąąäėæB(t©żi)Ęų╬÷Ż¼Ę┤ė│Ųõ░l(f©Ī)š╣╦«ŲĮ║═╦┘Č╚Ą─ūā╗»ęÄ(gu©®)┬╔ĪŻ
▀M(j©¼n)ąąäėæB(t©żi)Ęų╬÷Ż¼ę¬ūóęŌöĄ(sh©┤)┴ąųąĖ„éĆųĖś╦(bi©Īo)Š▀ėąĄ─┐╔▒╚ąįĪŻ┐é¾wĘČć·ĪóųĖś╦(bi©Īo)ėŗ╦ŃĘĮĘ©Īóėŗ╦ŃārĖ±║═ėŗ┴┐å╬╬╗Ż¼Č╝æ¬(y©®ng)įōŪ░║¾ę╗ų┬ĪŻĢrķgķgĖ¶ę╗░Ńę▓ę¬ę╗ų┬Ż¼Ą½ę▓┐╔ęįĖ∙ō■(j©┤)蹊┐─┐Ą─Ż¼▓╔╚Ī▓╗═¼Ą─ķgĖ¶Ų┌Ż¼╚ń░┤Üv╩ĘĢrŲ┌ĘųĪŻ×ķ┴╦Ž¹│²ĢrķgķgĖ¶Ų┌▓╗═¼Č°«a(ch©Żn)╔·Ą─ųĖś╦(bi©Īo)öĄ(sh©┤)ųĄ▓╗┐╔▒╚Ż¼┐╔▓╔ė├─ĻŲĮŠ∙öĄ(sh©┤)║═─ĻŲĮŠ∙░l(f©Ī)š╣╦┘Č╚üĒŠÄųŲäėæB(t©żi)öĄ(sh©┤)┴ąĪŻ┤╦═Ōį┌Įy(t©»ng)ėŗ╔ŽŻ¼įSČÓŠC║ŽųĖś╦(bi©Īo)╩Ū▓╔ė├ārųĄą╬æB(t©żi)üĒĘ┤ė│īŹ╬’┐é┴┐Ż¼╚ńć°ā╚(n©©i)╔·«a(ch©Żn)┐éųĄĪó╣żśI(y©©)┐é«a(ch©Żn)ųĄĪó╔ńĢ■╔╠ŲĘ┴Ń╩█┐éŅ~Ą╚ėŗ╦Ń▓╗═¼─ĻĘ▌Ą─░l(f©Ī)š╣╦┘Č╚ĢrŻ¼▒žĒÜŽ¹│²ārĖ±ūāäėę“╦žĄ─ė░ĒæŻ¼▓┼─▄š²┤_Ą─Ę┤ė│īŹ╬’┴┐Ą─ūā╗»ĪŻę▓Š═╩Ūšf▒žĒÜė├┐╔▒╚ārĖ±Ż©╚ńė├▓╗ūāār╗“ė├ārĖ±ųĖöĄ(sh©┤)š{(di©żo)š¹Ż®ėŗ╦Ń▓╗═¼─ĻĘ▌ŽÓ═¼«a(ch©Żn)ŲĘĄ─ārųĄŻ¼╚╗║¾▓┼─▄▀M(j©¼n)ąąī”▒╚ĪŻ
×ķ┴╦ė^▓ņ╬ęć°Įø(j©®ng)Ø·░l(f©Ī)š╣Ą─▓©äė▄ē█EŻ¼┐╔īóĖ„─Ļć°ā╚(n©©i)╔·«a(ch©Żn)┐éųĄĄ─░l(f©Ī)š╣╦┘Č╚ŠÄųŲĢrķgöĄ(sh©┤)┴ąŻ¼▓óō■(j©┤)ęį└LųŲ│╔Ū·ŠĆłDŻ¼┴Ņ╚╦Ą├ĄĮų▒ė^šJ(r©©n)ūRĪŻ
╦─ĪóųĖöĄ(sh©┤)Ęų╬÷Ę©
ųĖöĄ(sh©┤)╩ŪųĖĘ┤ė│╔ńĢ■Įø(j©®ng)Ø·¼F(xi©żn)Ž¾ūāäėŪķørĄ─ŽÓī”öĄ(sh©┤)ĪŻėąÅV┴x║═¬M┴xų«ĘųĪŻĖ∙ō■(j©┤)ųĖöĄ(sh©┤)╦∙蹊┐Ą─ĘČć·▓╗═¼┐╔ęįėąéĆ¾wųĖöĄ(sh©┤)ĪóŅÉųĖöĄ(sh©┤)┼c┐éųĖöĄ(sh©┤)ų«ĘųĪŻ
ųĖöĄ(sh©┤)Ą─ū„ė├Ż║ę╗╩Ū┐╔ęįŠC║ŽĘ┤ė│Å═(f©┤)ļsĄ─╔ńĢ■Įø(j©®ng)Ø·¼F(xi©żn)Ž¾Ą─┐é¾wöĄ(sh©┤)┴┐ūāäėĄ─ĘĮŽ“║═│╠Č╚Ż╗Č■╩Ū┐╔ęįĘų╬÷─│ĘN╔ńĢ■Įø(j©®ng)Ø·¼F(xi©żn)Ž¾Ą─┐éūāäė╩▄Ė„ę“╦žūāäėė░ĒæĄ─│╠Č╚Ż¼▀@╩Ūę╗ĘNę“╦žĘų╬÷Ę©ĪŻ▓┘ū„ĘĮĘ©╩ŪŻ║═©▀^ųĖöĄ(sh©┤)¾wŽĄųąĄ─öĄ(sh©┤)┴┐ĻP(gu©Īn)ŽĄŻ¼╝┘Č©Ųõ╦¹ę“╦ž▓╗ūāŻ¼üĒė^▓ņ─│ę╗ę“╦žĄ─ūāäėī”┐éūāäėĄ─ė░ĒæĪŻ
ė├ųĖöĄ(sh©┤)▀M(j©¼n)ąąę“╦žĘų╬÷ĪŻę“╦žĘų╬÷Š═╩Ūīó蹊┐ī”Ž¾ĘųĮŌ×ķĖ„éĆę“╦žŻ¼░č蹊┐ī”Ž¾Ą─┐é¾w┐┤│╔╩ŪĖ„ę“╦žūāäė╣▓═¼Ą─ĮY(ji©”)╣¹Ż¼═©▀^ī”Ė„éĆę“╦žĄ─Ęų╬÷Ż¼ī”蹊┐ī”Ž¾┐éūāäėųąĖ„ĒŚę“╦žĄ─ė░Ēæ│╠Č╚▀M(j©¼n)ąą£yČ©ĪŻę“╦žĘų╬÷░┤Ųõ╦∙蹊┐Ą─ī”Ž¾Ą─Įy(t©»ng)ėŗųĖś╦(bi©Īo)▓╗═¼┐╔Ęų×ķī”┐é┴┐ųĖś╦(bi©Īo)Ą─ūāäėĄ─ę“╦žĘų╬÷Ż¼ī”ŲĮŠ∙ųĖś╦(bi©Īo)ūāäėĄ─ę“╦žĘų╬÷ĪŻ
╬ÕĪóŲĮ║ŌĘų╬÷Ę©
ŲĮ║ŌĘų╬÷╩Ū蹊┐╔ńĢ■Įø(j©®ng)Ø·¼F(xi©żn)Ž¾öĄ(sh©┤)┴┐ūā╗»ī”Ą╚ĻP(gu©Īn)ŽĄĄ─ę╗ĘNĘĮĘ©ĪŻ╦³░čī”┴óĮy(t©»ng)ę╗Ą─ļpĘĮ░┤Ųõśŗ(g©░u)│╔ę¬╦žę╗ę╗┼┼┴ąŲüĒŻ¼Įo╚╦ęįš¹¾wĄ─Ė┼─ŅŻ¼ęį▒Ńė┌╚½ŠųüĒė^▓ņ╦³éāų«ķgĄ─ŲĮ║ŌĻP(gu©Īn)ŽĄĪŻŲĮ║ŌĻP(gu©Īn)ŽĄÅVĘ║┤µį┌ė┌Įø(j©®ng)Ø·╔·╗ŅųąŻ¼┤¾ų┴╚½ć°║Ļė^Įø(j©®ng)Ø·▀\ąąŻ¼ąĪų┴éĆ╚╦Įø(j©®ng)Ø·╩šų¦ĪŻŲĮ║ŌĘNŅÉĘ▒ČÓŻ¼╚ńžöš■ŲĮ║Ō▒ĒĪóä┌äė┴”ŲĮ║Ō▒ĒĪó─▄į┤ŲĮ║Ō▒ĒĪóć°ļH╩šų¦ŲĮ║Ō▒ĒĪó═Č╚ļ«a(ch©Żn)│÷ŲĮ║Ō▒ĒŻ¼Ą╚Ą╚ĪŻŲĮ║ŌĘų╬÷Ą─ū„ė├Ż║ę╗╩ŪÅ─öĄ(sh©┤)┴┐ī”Ą╚ĻP(gu©Īn)ŽĄ╔ŽĘ┤ė│╔ńĢ■Įø(j©®ng)Ø·¼F(xi©żn)Ž¾Ą─ŲĮ║ŌĀŅørŻ¼Ęų╬÷Ė„ĘN▒╚└²ĻP(gu©Īn)ŽĄŽÓ▀mæ¬(y©®ng)ĀŅørŻ╗Č■╩ŪĮę╩Š▓╗ŲĮ║ŌĄ─ę“╦ž║═░l(f©Ī)š╣?ji©”)ō┴”Ż╗╚²╩Ū└¹ė├ŲĮ║ŌĻP(gu©Īn)ŽĄ┐╔ęįÅ─Ė„ĒŚęčų¬ųĖś╦(bi©Īo)ųą═Ų╦Ń╬┤ų¬Ą─éĆäeųĖś╦(bi©Īo)ĪŻ
┴∙ĪóŠC║ŽįuārĘų╬÷
╔ńĢ■Įø(j©®ng)Ø·Ęų╬÷¼F(xi©żn)Ž¾═∙═∙╩ŪÕeŠCÅ═(f©┤)ļsĄ─Ż¼╔ńĢ■Įø(j©®ng)Ø·▀\ąąĀŅør╩ŪČÓĘNę“╦žŠC║Žū„ė├Ą─ĮY(ji©”)╣¹Ż¼Č°ŪęĖ„éĆę“╦žĄ─ūāäėĘĮŽ“║═ūāäė│╠Č╚╩Ū▓╗═¼Ą─ĪŻ╚ńī”║Ļė^Įø(j©®ng)Ø·▀\ąąĄ─įuārŻ¼╔µ╝░╔·╗ŅĪóĘų┼õĪó┴„═©ĪóŽ¹┘MĖ„éĆĘĮ├µŻ╗ī”Ų¾śI(y©©)Įø(j©®ng)Ø·ą¦ęµĄ─įuārŻ¼╔µ╝░╚╦ĪóžöĪó╬’║Ž└Ē└¹ė├║═╩ął÷õN╩█ĀŅørĪŻ╚ń╣¹ų╗ė├å╬ę╗ųĖś╦(bi©Īo)Ż¼Š═ļyęįū„│÷ŪĪ«ö(d©Īng)?sh©┤)─įuārĪŻ
▀M(j©¼n)ąąŠC║Žįuār░³└©╦─éĆ▓Į¾EŻ║
1.┤_Č©įuārųĖś╦(bi©Īo)¾wŽĄŻ¼▀@╩ŪŠC║ŽįuārĄ─╗∙ĄA(ch©│)║═ę└ō■(j©┤)ĪŻę¬ūóęŌųĖś╦(bi©Īo)¾wŽĄĄ─╚½├µąį║═ŽĄĮy(t©»ng)ąįĪŻ
2.╦č╝»öĄ(sh©┤)ō■(j©┤)Ż¼▓óī”▓╗═¼ėŗ┴┐å╬╬╗Ą─ųĖś╦(bi©Īo)öĄ(sh©┤)ųĄ▀M(j©¼n)ąą═¼Č╚┴┐╠Ä└ĒĪŻ┐╔▓╔ė├ŽÓī”╗»╠Ä└ĒĪó║»öĄ(sh©┤)╗»╠Ä└ĒĪóś╦(bi©Īo)£╩(zh©│n)╗»╠Ä└ĒĄ╚ĘĮĘ©ĪŻ
3.┤_Č©Ė„ųĖś╦(bi©Īo)Ą─ÖÓ(qu©ón)öĄ(sh©┤)Ż¼ęį▒ŻūCįuārĄ─┐ŲīW(xu©”)ąįĪŻĖ∙ō■(j©┤)Ė„éĆųĖś╦(bi©Īo)╦∙╠ÄĄ─Ąž╬╗║═ī”┐é¾wė░Ēæ│╠Č╚▓╗═¼Ż¼ąĶę¬ī”▓╗═¼ųĖś╦(bi©Īo)┘xėĶ▓╗═¼Ą─ÖÓ(qu©ón)öĄ(sh©┤)ĪŻ
4.ī”ųĖś╦(bi©Īo)▀M(j©¼n)ąąģR┐éŻ¼ėŗ╦ŃŠC║ŽĘųųĄŻ¼▓óō■(j©┤)┤╦ū„│÷ŠC║ŽįuārĪŻ
Ų▀ĪóŠ░ÜŌĘų╬÷
Įø(j©®ng)Ø·▓©äė╩Ū┐═ė^┤µį┌Ą─Ż¼╩Ū╚╬║╬ć°╝ęČ╝ļyęį═Ļ╚½▒▄├ŌĄ─ĪŻ╚ń║╬▒▄├Ō┤¾Ą─Įø(j©®ng)Ø·▓©äėŻ¼▒Ż│ųĮø(j©®ng)Ø·Ą─ĘĆ(w©¦n)Č©░l(f©Ī)š╣Ż¼ę╗ų▒╩ŪĖ„ć°š■Ė«║═Įø(j©®ng)Ø·ų«īŻ╝ęį┌║Ļė^š{(di©żo)┐ž║═øQ▓▀ųą├µ┼RĄ─ųžę¬šnŅ}Ż¼Š░ÜŌĘų╬÷š²╩Ū▀mæ¬(y©®ng)▀@ę╗ę¬Ū¾Č°«a(ch©Żn)╔·║═░l(f©Ī)š╣Ą─ĪŻŠ░ÜŌĘų╬÷╩Ūę╗ĘNŠC║ŽįuārĘų╬÷Ż¼┐╔Ęų×ķ║Ļė^Įø(j©®ng)Ø·Š░ÜŌĘų╬÷║═Ų¾śI(y©©)Š░ÜŌš{(di©żo)▓ķĘų╬÷ĪŻ
║Ļė^Įø(j©®ng)Ø·Š░ÜŌĘų╬÷ĪŻ╩Ūć°╝ęĮy(t©»ng)ėŗŠų20╩└╝o(j©¼)80─Ļ┤·║¾Ų┌ķ_╩╝ų°╩ųĮ©┴ó▒O(ji©Īn)£yųĖś╦(bi©Īo)¾wŽĄ║═įuārĘĮĘ©Ż¼Įø(j©®ng)▀^╩«ČÓ─ĻĢrķg║═▓╗öÓ═Ļ╔ŲŻ¼ęčą╬│╔ųŲČ╚Ż¼Č©Ų┌╠ß╣®Š░ÜŌĘų╬÷ł¾ĖµŻ¼ī”║Ļė^Įø(j©®ng)Ø·▀\ąąĀŅæB(t©żi)ŲĄĮŪńėĻ▒Ē║═ł¾Š»Ų„Ą─ū„ė├Ż¼▒Ńė┌ć°äš(w©┤)į║║═ėąĻP(gu©Īn)▓┐ķT╝░Ģr▓╔╚Ī║Ļė^š{(di©żo)┐ž┤ļ╩®ĪŻęįĮø(j©®ng)│ŻąįĄ─ąĪš{(di©żo)š¹Ż¼Ę└ų╣Įø(j©®ng)Ø·Ą─┤¾Ų┤¾┬õĪŻ
Ų¾śI(y©©)Š░ÜŌš{(di©żo)▓ķĘų╬÷ĪŻ╩Ū╚½ć°Ą─┤¾ųąą═Ė„ŅÉŲ¾śI(y©©)ųąŻ¼▓╔╚Ī│ķśėš{(di©żo)▓ķĄ─ĘĮĘ©Ż¼═©▀^墊ĒĄ─ą╬╩ĮŻ¼ūīŲ¾śI(y©©)žō(f©┤)ž¤(z©”)╚╦╗ž┤ėąĻP(gu©Īn)Ūķør┼ąöÓ║═ŅA(y©┤)Ų┌ĪŻā╚(n©©i)╚▌Ęų×ķā╔ŅÉŻ║ę╗╩Ūī”║Ļė^Įø(j©®ng)Ø·┐é¾wĄ─┼ąöÓ║═ŅA(y©┤)Ų┌Ż╗ę╗╩Ūī”Ų¾śI(y©©)Įø(j©®ng)ĀIĀŅørĄ─┼ąöÓ║═ŅA(y©┤)Ų┌Ż¼╚ń«a(ch©Żn)ŲĘėåå╬ĪóįŁ▓─┴Ž┘Å▀M(j©¼n)ĪóārĖ±Īó┤µžøĪóŠ═śI(y©©)Īó╩ął÷ąĶŪ¾Īó╣╠Č©┘Y«a(ch©Żn)═Č┘YĄ╚ĪŻ
░╦ĪóŅA(y©┤)£yĘų╬÷
║Ļė^Įø(j©®ng)Ø·øQ▓▀║═╬óė^Įø(j©®ng)Ø·øQ▓▀Ż¼▓╗āHąĶę¬┴╦ĮŌĮø(j©®ng)Ø·▀\ąąųąęčĮø(j©®ng)░l(f©Ī)╔·┴╦Ą─īŹļHŪķørŻ¼Č°ŪęĖ³ąĶę¬ŅA(y©┤)ęŖ╬┤üĒīó░l(f©Ī)╔·Ą─ŪķørĪŻĖ∙ō■(j©┤)ęčų¬Ą─▀^╚ź║═¼F(xi©żn)į┌═Ų£y╬┤üĒŻ¼Š═╩ŪŅA(y©┤)£yĘų╬÷ĪŻ
Įy(t©»ng)ėŗŅA(y©┤)£yī┘ė┌Č©┴┐ŅA(y©┤)£yŻ¼╩ŪęįöĄ(sh©┤)ō■(j©┤)Ęų╬÷×ķų„Ż¼į┌ŅA(y©┤)£yųąĮY(ji©”)║ŽČ©ąįĘų╬÷ĪŻĮy(t©»ng)ėŗŅA(y©┤)£yĄ─ĘĮĘ©┤¾ų┬┐╔Ęų×ķā╔ŅÉŻ║ę╗ŅÉ╩Ūų„ę¬Ė∙ō■(j©┤)ųĖś╦(bi©Īo)ĢrķgöĄ(sh©┤)┴ąūį╔Ēūā╗»┼cĢrķgĄ─ę└┤µĻP(gu©Īn)ŽĄ▀M(j©¼n)ąąŅA(y©┤)£yŻ¼ī┘ė┌ĢrķgöĄ(sh©┤)┴ąĘų╬÷Ż╗┴Ēę╗ŅÉ╩ŪĖ∙ō■(j©┤)ųĖś╦(bi©Īo)ų«ķgŽÓ╗źė░ĒæĄ─ę“╣¹ĻP(gu©Īn)ŽĄ▀M(j©¼n)ąąŅA(y©┤)£yŻ¼ī┘ė┌╗žÜwĘų╬÷ĪŻ
ŅA(y©┤)£yĘų╬÷Ą─ĘĮĘ©ėą╗žÜwĘų╬÷Ę©Īó╗¼äėŲĮŠ∙Ę©ĪóųĖöĄ(sh©┤)ŲĮ╗¼Ę©Īóų▄Ų┌Ż©╝Š╣Ø(ji©”)Ż®ūā╗»Ęų╬÷║═ļSÖCūā╗»Ęų╬÷Ą╚ĪŻ▒╚▌^Å═(f©┤)ļsĄ─ŅA(y©┤)£yĘų╬÷ąĶę¬Į©┴óėŗ┴┐Įø(j©®ng)Ø·─Żą═Ż¼Ū¾ĮŌ─Żą═ųąĄ─ģóöĄ(sh©┤)ėųėąįSČÓĘĮĘ©ĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://www.oesoe.com/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷ĘĮĘ©ĮŌūxęį╝░ŽÓĻP(gu©Īn)╣żŠ▀ĮķĮB
▒Š╬─ŠW(w©Żng)ųĘŻ║http://www.oesoe.com/html/support/11121518954.html



▀xą═ųąą─")
¾w“×ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")